
아보카도 Blog
자료구조, 알고리즘 3주차: 정렬, 스택, 큐, 해쉬, 아주 어려운 연습문제들... 본문
이번 주에는 큰 개념 두개를 배웠다.
하나는 정렬이오
또 하나는 스택과 큐에서 구현할 수 있는 메소드들이다.
이번주는 연습 문제를 푸는 데 시간이 굉장히 많이 걸렸다.
찬찬히 살펴보자.
1. 정렬 Sort
정렬이란 데이터를 순서대로 나열하는 방법이다.
첫째와 둘째를 비교하고, 둘째와 셋째를 비교하면서 오랜 시간이 걸리는 버블 정렬,
배열 전체를 훑어보고 가장 작은값부터 0번째 인덱스에 넣고, 그 다음 작은 값을 1번째 인덱스에 넣으면서 정렬하는 선택정렬,
1번째 인덱스에 있는 데이터를 0번째 인덱스와 비교하고, 2번째 인덱스에 있는 데이터를 1번째, 0번째 인덱스와 비교하면서 중간에 끼워넣는 삽입정렬,
배열을 각각의 배열로 쪼개서 각 배열을 토너먼트식으로 합치는 병합정렬에 대해 배웠다.
각각의 정렬을 코드로 적어보면 다음과 같다.
input = [9, 5, 2, 4, 1]
def bubble_sort(array):
n = len(array)
for i in range(n - 1):
for j in range(n - 1 - i):
if array[j] > array[j + 1]:
array[j], array[j + 1] = array[j + 1],array[j]
return
bubble_sort(input)
print(input)
def selection_sort(array): # min_index를 설정해주어야 한다
n = len(array)
for i in range(n - 1):
min_index = i
for j in range(n - i):
if array[i + j] < array[min_index]:
min_index = i + j
array[i], array[min_index] = array[min_index],array[i]
return
selection_sort(input)
print(input)
def insertion_sort(array): #뒤에서 앞으로 비교하는 거라 j 반복문이 i까지다.
n = len(array)
for i in range(1, n):
for j in range(i):
if array[i - j - 1] > array[i - j]:
array[i - j - 1],array[i - j] = array[i - j],array[i - j - 1]
else:
break # 작거나 같으면 그냥 냅둔다
return
insertion_sort(input)
print(input)
array = [8,4,2,7,5,9,1,8,11,4,78]
#1단계 merge
def merge(array1, array2):
#빈 배열, 인덱스를 저장할 변수 각각을 만든다
array_c = []
array1_index = 0
array2_index = 0
while array1_index < len(array1) and array2_index < len(array2):
if array1[array1_index] < array2[array2_index]:
array_c.append(array1[array1_index])
array1_index += 1
else:
array_c.append(array2[array2_index])
array2_index += 1
if array1_index == len(array1):
while array2_index < len(array2):
array_c.append(array2[array2_index])
array2_index += 1
if array2_index == len(array2): # 만약 배열2이 끝까지 갔으면 = 배열1가 남아있다
while array1_index < len(array1): # 배열1이 끝까지 갈때까지
array_c.append(array1[array1_index]) # 배열1의 내용을 배열c에 넣어주면 된다
array1_index += 1
return array_c
#2단계 merge_sort
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array) // 2
left_array = merge_sort(array[:mid])
right_array = merge_sort(array[mid:])
return merge(left_array, right_array)
print(merge_sort(array))
2. 스택 Stack

스택은 한쪽 끝으로만 자료를 넣고 뺄 수 있는 자료구조로,
LIFO Last In First Out 형식을 띈다.
넣은 순서를 쌓아두는 기능이 있다.
스택이라는 자료 구조에서 제공하는 기능에는
top에 데이터를 넣는 push,
top 데이터 뽑아 없애는 pop,
top데이터 조회하는 peek이 있다.
파이썬에서 이 코드들을 구현하면 다음과 같다.
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Stack:
def __init__(self):
self.head = None
def push(self, value):
new_head = Node(value)
new_head.next = self.head
self.head = new_head
def pop(self): # delete_head 임시저장
if self.is_empty():
return None
delete_head = self.head
self.head = self.head.next
return delete_head
def peek(self):
if self.is_empty():
return None
return self.head.data
def is_empty(self):
return self.head is None
stack = Stack()
stack.push(1)
print(stack)
print(stack.is_empty())
print(stack.peek())
stack.push(2)
print(stack.peek())
3. 큐 Queue
큐는 한쪽 끝으로 자료를 넣고, 반대쪽에서는 자료를 뺄 수 있는 선형 구조이다.
FIFO First In First Out 구조를 띈다. 순서대로 처리되어야 하는 일에 필요하다.
큐는 데이터를 넣고 뽑는 것을 자주하는 자료구조이기 때문에 링크드리스트와 유사하게 구현된다.
큐라는 자료구조에서 제공하는 기능에는
맨 뒤에 데이터를 추가하는 enqueue,
맨 앞의 데이터를 뽑아 없애는 dequeue,
맨 앞 head를 조회하는 peek이 있다.
파이썬에서 이들을 코드로 구현하면 다음과 같다.
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Queue:
def __init__(self):
self.head = None
self.tail = None
def enqueue(self, value):
new_node = Node(value)
if self.is_empty():
self.head = new_node
self.tail = new_node
return
self.tail.next = new_node
self.tail = new_node
return
def dequeue(self): #delete_head에 임시저장
if self.is_empty():
return None
delete_head = self.head
self.head = self.head.next
return delete_head.data
def peek(self):
if self.is_empty():
return None
return self.head.data
def is_empty(self):
return self.head is None
queue = Queue()
queue.enqueue(3)
print(queue)
print(queue.peek())
queue.enqueue(4)
print(queue.peek())
queue.enqueue(5)
print(queue.peek())
print(queue.dequeue())
print(queue.peek())
print(queue.dequeue())
print(queue.is_empty())
print(queue.dequeue())
print(queue.is_empty())
4. 해쉬 Hash
해쉬 개념을 알기 앞서 해쉬 테이블에 대해 먼저 살펴보자.
해쉬테이블은 key와 data를 저장함으로써
즉각적으로 데이터를 받아와 업데이트하고 싶을 때 사용하는 자료구조이다.
해쉬테이블은 곧 딕셔너리고, 내부적으로는 배열을 사용한다.
이제 해쉬 함수 Hash Function 에 대해 알아보자.
해쉬함수는 임의의 길이를 갖는 메세지를 입력하여 고정된 길이의 해쉬값을 출력하는 것이다.
배열의 길이로 나눈 나머지값을 써주는 게 핵심이다.
정리하자면,
해쉬 테이블의 내부 구현은
키를 해쉬 함수를 통해 임의의 값으로 변경한 뒤
배열의 인덱스로 변환하여 해당하는 값에 데이터를 저장하는 것이다.
그렇기 때문에 즉각적으로 데이터를 찾고, 추가할 수 있다.
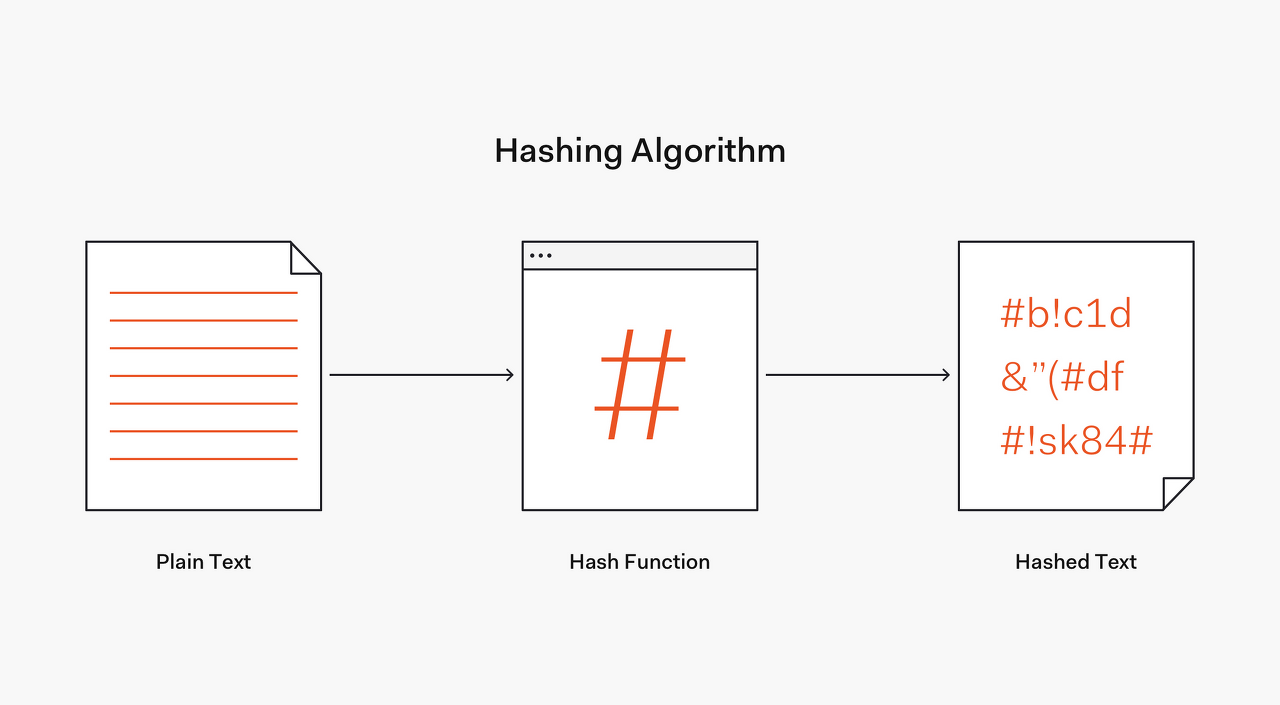
해쉬함수를 딕셔너리로 구현해보면 다음과 같다.
딕셔너리에는 put과 get 함수가 필요하다.
put은 key에 value를 저장하는 함수이고,
get은 key에 해당하는 value를 가져오는 함수이다.
첫번째 시도:
class Dict:
def __init__(self):
self.items = [None] * 8
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index] = value
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index]
my_dict = Dict()
my_dict.put("test", 3)
print(my_dict.get("test")) # 3이 반환되어야 합니다!
하지만 해쉬값이 같을 때 충돌이 발생한다.
여기에서 충돌은 같은 배열의 인덱스로 매핑이 되어서 데이터를 덮어쓰는 결과가 일어난 것이다.
여기에서 충돌을 해결하는 방법은 1. 체이닝 2.개방주소법이 있는데 우리는 체이닝만 자세히 배웠다.
체이닝은 링크드리스트를 사용하여 연결지어 해결하는 방법이다.
각 인덱스마다 LinkedTuple이 존재한다는 것을 생각하면 쉽다.
두번째 시도:
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index].add(key, value)
# 만약, 입력된 key가 "fast" 인데 index 값이 2가 나왔다.
# 현재 self.items[2] 가 [("slow", "느린")] 이었다!
# 그렇다면 새로 넣는 key, value 값을 뒤에 붙여주자!
# self.items[2] == [("slow", "느린") -> ("fast", "빠른")] 이렇게!
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index].get(key)
# 만약, 입력된 key가 "fast" 인데 index 값이 2가 나왔다.
# 현재 self.items[2] 가 [("slow", "느린") -> ("fast", "빠른")] 이었다!
# 그렇다면 그 리스트를 돌면서 key 가 일치하는 튜플을 찾아준다.
# ("fast", "빠른") 이 일치하므로 "빠른" 이란 값을 돌려주자!
5. 연습문제1: 출석체크
모든 학생 이름 배열과 출석 학생 배열이 주어질 때, 결석한 학생 이름 리턴하기
all_students = ["나연", "정연", "모모", "사나", "지효", "미나", "다현", "채영", "쯔위"]
present_students = ["정연", "모모", "채영", "쯔위", "사나", "나연", "미나", "다현"]
def get_absent_student(all_array, present_array):
dict = {}
for key in all_array:
dict[key] = True # 아무 값이나 넣어도 상관 없습니다! 여기서는 키가 중요한거니까요
for key in present_array: # dict에서 key 를 하나씩 없앱니다
del dict[key]
for key in dict.keys(): # key 중에 하나를 바로 반환합니다! 한 명 밖에 없으니 이렇게 해도 괜찮습니다.
return key
print(get_absent_student(all_students, present_students))
print("정답 = 예지 / 현재 풀이 값 = ",get_absent_student(["류진","예지","채령","리아","유나"],["리아","류진","채령","유나"]))
print("정답 = RM / 현재 풀이 값 = ",get_absent_student(["정국","진","뷔","슈가","지민","RM"],["뷔","정국","지민","진","슈가"]))
6. 연습문제 2: 쓱 최대로 할인 적용하기
가격 배열과 쿠폰 배열을 통해 최대로 할인 받을 때 내야하는 금액은?
가장 비싼 금액이 가장 많이 할인받아야 하므로 둘다 내림차순 정렬 .sort(reverse=True)한다.
가격 배열의 인덱스 수와 쿠폰 배열의 인덱스 수가 다를 수 있으므로 경우를 나누어서 while문을 2개 써줘야 한다.
shop_prices = [30000, 2000, 1500000]
user_coupons = [20, 40]
def get_max_discounted_price(prices, coupons):
prices.sort(reverse=True)
coupons.sort(reverse=True)
price_index = 0
coupon_index = 0
max_discounted_price = 0
while price_index < len(prices) and coupon_index < len(coupons):
max_discounted_price += prices[price_index] * (100-coupons[coupon_index]) / 100
price_index += 1
coupon_index += 1
while price_index < len(prices):
max_discounted_price += prices[price_index] # 나머지 가격들은 쿠폰 쓰지 않고 그냥 뒤에 더해준다.
price_index += 1
return max_discounted_price
print("정답 = 926000 / 현재 풀이 값 = ", get_max_discounted_price([30000, 2000, 1500000], [20, 40]))
print("정답 = 485000 / 현재 풀이 값 = ", get_max_discounted_price([50000, 1500000], [10, 70, 30, 20]))
print("정답 = 1550000 / 현재 풀이 값 = ", get_max_discounted_price([50000, 1500000], []))
print("정답 = 1458000 / 현재 풀이 값 = ", get_max_discounted_price([20000, 100000, 1500000], [10, 10, 10]))7. 연습문제 3: 올바른 괄호
올바른 괄호이면 T, 아니면 F 반환하기
닫힌 괄호가 나오면 바로 직전에 열린 괄호가 있는지 확인해야 한다. 따라서 stack이 필요하다
열린 괄호들을 저장해놓을 배열이 필요하다. 그래야 열린 괄호들이 끝까지 닫혀있는지 확인할 수 있으니까.
s = "(())())))"
def is_correct_parenthesis(string):
# 빈 배열을 선언하고 안에 열린 괄호들을 저장한다
stack = []
# 닫는 괄호가 나오면 바로 직전에 열린 괄호가 있는지 확인한다 stack
# 이 과정을 반복한다
for i in range(len(string)): #string에 있는 모든 원소 확인한다 (반복)
if string[i] == "(":
stack.append(i) # (가 들어있다는 여부를 저장한 것
elif string[i] == ")": # )가 먼저 나온 상황에서
if len(stack) == 0: # 바로 직전에 (가 없다면 False 반환
return False
stack.pop() # Top 데이터 뽑아 없애기 (11번째 줄에서 저장한 내용을 없애준 것)
# 반복 후에도 배열에 (얘가 남아있다면 짝이 안맞는다는 뜻이니 False를 반환한다
if len(stack) !=0:
return False
# 이 모든 조건을 충족하면 True 값을 반환한다.
else:
return True
print(is_correct_parenthesis(s))8. 연습문제 4: 멜론 베스트 앨범 뽑기
얘는 아주 어려웠다... 단계를 여러번 나누어서 풀어야 한다.
일단 구하려는 값은 조건 3개에 따라 베스트 앨범에 들어갈 노래의 인덱스를 순서대로 반환하는 것이다.
결과값은 인덱스 값으로 나와야 한다. 이에 따른 단계는 다음과 같다.
1. 장르 정렬: 장르별로 총 수를 세어서 비교해야 한다
2. 재생 수 고려하기 위해서 장르 내의 정렬이 필요하다.
장르별 key에 인덱스와 재생수를 배열로 묶어 배열에 저장해야 한다.
여기에서 인덱스는 for 문을 반환하기 위해서 필요하고, 재생수는 정렬을 위해 필요하다.
3. 딕셔너리의 key와 value(인덱스와 재생수)를 배열 형태로 추출하기
key=lambda item: item[1] 새롭게 적어줘야 하는 것들이 많았다.
4. 각 장르별 1순위, 2순위 곡들을 result 배열에 추가해서 반환하기
재생 수가 많은 요소 순으로 정렬하고 인덱스를 반환한다.
genres = ["classic", "pop", "classic", "classic", "pop"]
plays = [500, 600, 150, 800, 2500]
def get_melon_best_album(genre_array, play_array):
#1단계
# 장르 정렬: 장르별 총 수 세기
n = len(genre_array) # 장르 원소 총 개수
genre_total_play_dict = {}
#2단계
# 재생수도 고려. 장르 내의 정렬 필요: 장르별 key에 재생수와 인덱스를 배열로 묶어 배열에 저장
# 재생수 for 정렬, 인덱스 for 반환
genre_index_play_array_dict = {}
for i in range(n): # 장르 전체 둘러보기
genre = genre_array[i]
play = play_array[i]
if genre not in genre_total_play_dict: #이 장르가 처음 보는 애라면
genre_total_play_dict[genre] = play #그 장르에 재생 수를 처음으로 더해줌
genre_index_play_array_dict[genre] = [[i, play]] #인덱스와 재생수도 다른 배열에 저장
else:
genre_total_play_dict[genre] += play #이 장르가 이미 딕셔너리에 있다면 수를 더해주면 됨. 나중에 총수 비교하기 위함
genre_index_play_array_dict[genre].append([i,play]) #장르별 key에 재생수와 인덱스 배열로 묶어 저장
print(genre_total_play_dict)
# {'classic': 1450, 'pop': 3100} 이 출력됩니다!
print(genre_index_play_array_dict)
# {'classic': [[0, 500], [2, 150], [3, 800]], 'pop': [[1, 600], [4, 2500]]} 이 출력됩니다!
#3단계
# genre_total_play_dict 정렬해서 재생 수가 높은 장르 뽑기위해서는 먼저
# dict.items() 딕셔너리의 키 - 값을 배열 형태로 추출하기
# sorted(genre_total_play_dict.items(), key=lambda item: item[1], reverse=True)
#람다: 어던 것으로 정렬할지에 대해 정해주는 기준
#1450이라는 밸류 값을 기준으로 정렬
#내림차순 정렬
sorted_genre_play_array = sorted(genre_total_play_dict.items(), key=lambda item: item[1], reverse=True)
print(sorted_genre_play_array)
#4단계
#각 장르별 1순위, 2순위 곡들을 result 배열에 추가해서 반환. 재생수가 많은 애들 순으로 정렬, 인덱스 반환
result = []
for genre, _value in sorted_genre_play_array: #여기서 value 앞에 _는 왜 붙여준거지?
index_play_array = genre_index_play_array_dict[genre] #딕셔너리에서 재생수 배열만 꺼내 따로 선언한다 ex.[[1,600],[4,2500]]
sorted_by_play_and_index_play_index_array = sorted(index_play_array, key=lambda item: item[1], reverse=True) #두번째 갑신 재생수로 정렬 item[1]
for i in range(len(sorted_by_play_and_index_play_index_array)):
if i > 1:
break
result.append(sorted_by_play_and_index_play_index_array[i][0]) #정렬된 배열 안의 값들을 rsult 배열에 추가해준다. 인덱스 반환 위해 [0]
return result
print("정답 = [4, 1, 3, 0] / 현재 풀이 값 = ", get_melon_best_album(["classic", "pop", "classic", "classic", "pop"], [500, 600, 150, 800, 2500]))
print("문제 하나 더 예시")
print("정답 = [0, 6, 5, 2, 4, 1] / 현재 풀이 값 = ", get_melon_best_album(["hiphop", "classic", "pop", "classic", "classic", "pop", "hiphop"], [2000, 500, 600, 150, 800, 2500, 2000]))
휴우... 너무 어려운 주였다.
2,3주차는 반드시 복습이 필요하다.
일단 진도를 따라가야 하니 4,5주차도 천천히 나가고
나중에 두 번씩 더 보는 것을 목표로 하자. 화이팅~~
'자료구조, 알고리즘' 카테고리의 다른 글
| 자료구조, 알고리즘 5주차 (0) | 2022.12.12 |
|---|---|
| 자료구조, 알고리즘 4주차: 완전이진트리, 힙, DFS&BFS, Dynamic Programming (1) | 2022.11.29 |
| 알고리즘 강의 3일차: 스택(push, pop, peek), 큐(enqueue, dequeue, peek), 정렬(버블, 선택, 삽입) (0) | 2022.11.25 |
| 자료구조, 알고리즘 2주차: 배열, 링크드리스트, 이진탐색, 재귀함수 (0) | 2022.11.24 |
| 알고리즘 강의 2일차: 시간 복잡도, 배열, 링크드리스트(Class, append, get_node, add_node) (0) | 2022.11.24 |


