
아보카도 Blog
자료구조, 알고리즘 2주차: 배열, 링크드리스트, 이진탐색, 재귀함수 본문
와 넘 어렵다! 특히나 숙제에서 배달 음식이 메뉴에 있는건지 이진탐색으로 확인하는 것과(전에 만든 폼을 활용)
숫자들을 +- 해서 원하는 목표값을 도달하는 경우의 수를 세는 것이 어려웠다.
그래도 첫번째 문제였던 끝에서 k번째 값 출력하기는 내 힘으로 풀었다. 나머지 두 문제도 스스로 해결할 수 있기를...
이번 주에 배운 내용들을 살펴보면,
1. 배열과 링크드리스트
배열과 링크드리스트를 호텔 방을 옮기는 일화와 기차 화물 칸을 옮기는 일화로 재미있게 풀어 배웠다.
정리하자면, 데이터에 접근이 빈번하다면 배열을, 삽입/삭제가 빈번하다면 링크드리스트를 사용하는 것이 효율적이다.
2. 클래스Class와 객체 Object, 생성자Constructor, 메소드 Method
사람이라는 클래스 안에 수정, 미희이라는 객체가 있다.
클래스 안에는 생성자가 객체에게 데이터를 넣어주거나 행동을 실행할 수 있게 한다.
파이썬에서 생성자 함수의 이름은 __init__(self)로 정해져 있다.
이때 self는 자기 자신을 가리킨다. 뭐 호출하면 자동으로 입력되니 편하다.
메소드는 클래스 내부의 함수로, 각 개체의 변수를 사용해서 구현된다.
class Person:
def __init__(self, param_name):
print("hihihi", self)
self.name = param_name
def talk(self):
print("안녕하세요 저는", self.name, "입니다")
person_1 = Person("유재석") # hihihi <__main__.Person object at 0x1067e6d60> 이 출력됩니다!
print(person_1.name) # 유재석
person_1.talk() # 안녕하세요 저는 유재석 입니다
3. 링크드 리스트 append
class LinkedList:
def __init__(self, value):
self.head = Node(value) # head 에 시작하는 Node 를 연결합니다.
def append(self, value): # LinkedList 가장 끝에 있는 노드에 새로운 노드를 연결합니다.
cur = self.head
while cur.next is not None: # cur의 다음이 끝에 갈 때까지 이동합니다.
cur = cur.next
cur.next = Node(value)
linked_list = LinkedList(5)
linked_list.append(12)
# 이렇게 되면 5 -> 12 형태로 노드를 연결한 겁니다!
linked_list.append(8)
# 이렇게 되면 5 -> 12 -> 8 형태로 노드를 연결한 겁니다!4. 링크드 리스트 print_all
...
def print_all(self):
cur = self.head
while cur is not None:
print(cur.data)
cur = cur.next
...
linked_list.print_all()5. 링크드 리스트 get_node
...
def get_node(self, index):
node = self.head
count = 0
while count < index:
node = node.next
count += 1
return node
...6. 링크드 리스트 add_node
...
def add_node(self, index, value):
new_node = Node(value)
if index == 0:
new_node.next = self.head
self.head = new_node
return
node = self.get_node(index - 1)
next_node = node.next
node.next = new_node
new_node.next = next_node
...7. 링크드 리스트 delete_node
...
def delete_node(self, index):
if index == 0:
self.head = self.head.next
return
node = self.get_node(index - 1)
node.next = node.next.next
...
8. 연습문제 1: 두 링크드 리스트의 합 계산
...
def get_linked_list_sum(linked_list_1, linked_list_2):
sum_1 = _get_linked_list_sum(linked_list_1)
sum_2 = _get_linked_list_sum(linked_list_2)
return sum_1 + sum_2
def _get_linked_list_sum(linked_list):
sum = 0
head = linked_list.head
while head is not None:
sum = sum * 10 + head.data
head = head.next
return sum
...
9. 이진탐색 Binary Search (비교: 순차탐색 Sequential Search)
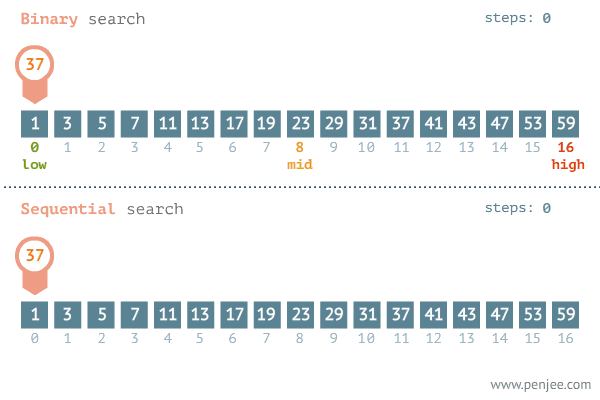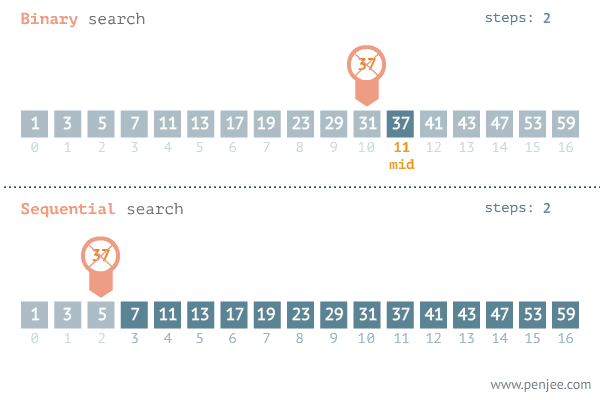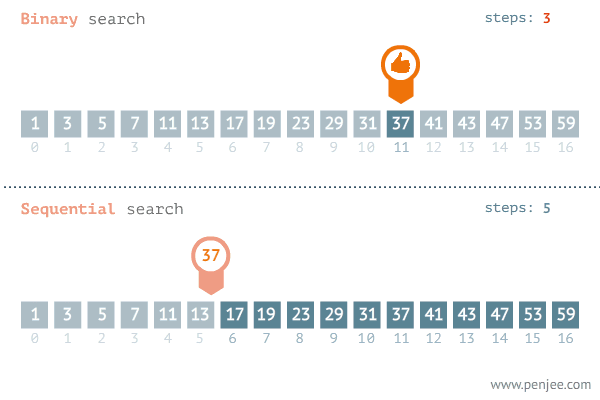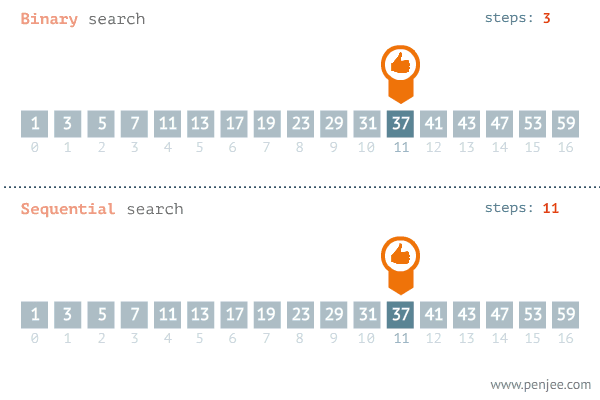
이진탐색은 타겟값을 찾는데 있어 배열 또는 리스트의 원소를 반으로 쪼갠 후 각각 조사하고
그 다음단계로 넘어가 반으로 쪼개고 조사하고를 반복하면서 탐색하는 방법이다.
이진탐색이 이분탐색보다 효율적이다.
또한 일정한 규칙으로 정렬되어 있는 데이터에서만 이진탐색이 가능하다.
//라는 연산자를 통해 소수점 이하의 수를 버리고 몫만 나타냄으로써 이진탐색이 연속적으로 시행될 수 있게 한다.

또한 다음 시도에서 최솟값에 (시돗값+1)을, 최댓값에 (시돗값-1)을 놓는 것에 주의하자
finding_target = 14
finding_numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16]
def is_existing_target_number_binary(target, array):
current_min = 0
current_max = len(array) - 1
current_guess = (current_min + current_max) // 2
while current_min <= current_max:
if array[current_guess] == target:
return True
elif array[current_guess] < target:
current_min = current_guess + 1
else:
current_max = current_guess - 1
current_guess = (current_min + current_max) // 2
return False
result = is_existing_target_number_binary(finding_target, finding_numbers)
print(result)
10. 재귀함수 Recursive Functions
재귀함수란 자기 자신을 호출하는 함수로, 간결하고 효율성 있는 코드를 작성하기 위해 쓰인다.
재귀함수는 언제 쓰느냐, 특정 구조가 반복되는 양상을 띌 때 재귀함수를 씀으로써 문제를 축소할 수 있을 때 쓴다.
재귀함수를 쓸 때 주의할 점은 탈출지점을 명시해주어야 한다는 점이다.
예를 들면 팩토리얼은 다음과 같이 쓸 수 있다.
def factorial(n):
if n == 1:
return 1
return n * factorial(n - 1)
print(factorial(60))11. 연습문제 2: 회문검사 Palindrome check
앞뒤가 똑같은 단어나 문장을 회문이라고 하며, 재귀함수를 이용해 해당 문자열이 회문인지 확인할 수 있다.
이 문제를 풀면서 문자열 슬라이싱이라는 것을 배웠다. 문자열[시작 인덱스:끝 인덱스]
뒤에서부터 자르고 싶을 땐 -1을 해주면 된다.
input = "abcba"
def is_palindrome(string):
if len(string) <= 1:
return True
if string[0] != string[-1]:
return False
return is_palindrome(string[1:-1])
print(is_palindrome(input))
12. 연습문제 3 링크드 리스트 끝에서 K 번째 값 출력하기
일단 내 시도는 getCount라는 함수를 만들어서 리스트의 끝지점의 수를 세어준 뒤,
k번째 값을 찾는 함수에서 k만큼 빼어서 계산하는 것이었다.
시도1:
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self, value):
self.head = Node(value)
def append(self, value):
cur = self.head
while cur.next is not None:
cur = cur.next
cur.next = Node(value)
# 링크드 리스트의 마지막 노드 인덱스를 세어보자
def getCount(self):
node = self.head
count = 0
while (node):
count += 1
node = node.next
return count
def get_kth_node_from_last(self, k):
node = self.head
count = 0
while count < (self.getCount()-k): #getCount()를 호출해서 뒤에서 k번째 요소까지 이동하며 count +1 해준다.
node = node.next
count += 1
return node
linked_list = LinkedList(6)
linked_list.append(7)
linked_list.append(8)
print(linked_list.get_kth_node_from_last(2).data) # 7이 나와야 합니다!
하지만 예시 답안을 보니 굳이 새로운 함수를 만들고 그를 다른 함수 내부에서 호출하지 않아도
하나의 함수 안에서 length라는 변수를 지정해준 뒤 while문이 반복될 때마다 +1씩 더해주면 된다는 것을 알았다.
개선방안1:
def get_kth_node_from_last(self, k):
length = 1 # 시작 노드의 길이를 센다
cur = self.head
while cur.next is not None:
cur = cur.next
length += 1
end_length = length - k #끝에서부터 k번째 요소
cur = self.head #초기화
for i in range(end_length): # i번째 인덱스부터 (끝에서부터 k)까지 옮긴다
cur = cur.next
return cur #끝에서 k번째 값 출력하지만 이도 효율적인 방법은 아니라는데,
그 이유는 리스트의 길이를 전부 알지 않아도 2개의 포인터를 사용해서 풀 수 있기 때문이다.
k만큼 떨어져있는 포인터 두 개를 움직이는 것이 관건이다.
개선방안2:
# 두 개의 포인터 사용하기: k만큼 길이가 떨어진 포인터 두 개 두고 한 칸씩 이동
def get_kth_node_from_last(self, k):
slow = self.head
fast = self.head
for i in range(k): # k만큼의 길이
fast = fast.next # 앞 포인터를 k만큼 이동한다
while fast is not None: # 앞 포인터가 맨 마지막으로 갈때까지 앞 뒤 포인터를 간격 K를 사이에 두고 일정하게 움직인다
slow = slow.next
fast = fast.next
return slow # 뒤에 있는 포인터를 출력한다 = 뒤에서 k번째 값 출력
13. 연습문제 4 배달의 민족 배달 가능 여부
이 문제는 내가 주문한 품목들이 상점의 메뉴에 모두 포함이 되어있는지를 확인하는 것이었다.
이진탐색을 어떻게 만들어야할지 몰라 자연어로 적었다.
하지만 전 숫자 배열에서 타겟 숫자 찾을 때 작성한 이진탐색 코드를 그대로 재사용하면 된다는 것을 알게 되었다.
이진탐색하기 위해 정렬이 필요하다는 것에 포커스를 맞추었을 땐 다음과 같은 해답이 나온다.
shop_menus = ["만두", "떡볶이", "오뎅", "사이다", "콜라"]
shop_orders = ["오뎅", "콜라", "만두"]
def is_available_to_order(menus, orders):
menus.sort()
for order in orders:
if not is_existing_target_number_binary(menus, orders):
return False
return True
# 전에 만든 이진탐색 재사용
def is_existing_target_number_binary(target, array):
current_min = 0
current_max = len(array) - 1
current_guess = (current_min + current_max) // 2
while current_min <= current_max:
if array[current_guess] == target:
return True
elif array[current_guess] < target:
current_min = current_guess + 1
else:
current_max = current_guess - 1
current_guess = (current_min + current_max) // 2
return False
result = is_available_to_order(shop_menus, shop_orders)
print(result)하지만 이도 효율적인 방법이 아니라고 하니,
그 이유는 정렬하지 않고도 리스트를 집합set(중복을 허락하지 않음)으로 전환하여
특정한 문자열이 배열에 존재하는지만 확인하면 되기 때문이다. 이 경우 코드가 훨씬 간단해진다.
개선한 코드:
def is_available_to_order(menus, orders):
menus_set = set(menus) #정렬 필요없이 집합 자료형 사용
for order in orders:
if order not in menus_set:
return False
return True
14. 연습문제 5 더하거나 빼거나
이 문제가 이번 2주차에서 본 문제 중 가장 어려웠다.
그 이유는 알고리즘을 생각해내기가 익숙치 않았기 때문이다.
이런 확장형 문제를 풀기 위해서는 구조를 축소할 수 있는가? 라는 물음에서 시작해야 한다.
이 문제는 (마지막) 원소를 더할지 뺄지에 따라 일정한 구조가 반복되기 때문에 축소가 가능하다.
즉, N의 길이의 배열에서 더하거나 뺀 모든 경우의 수 += N-1 길이의 배열에서 마지막 원소를 더하거나 뺀 경우의 수이다.
우선 가능한 계산 결과를 모두 구하는 방법은 다음과 같다.
numbers = [1, 1, 1, 1, 1]
target_number = 3
result = [] # 모든 경우의 수를 담기 위한 배열
def get_all_ways_to_by_doing_plus_or_minus(array, current_index, current_sum, all_ways):
if current_index == len(array): # 탈출조건
all_ways.append(current_sum) # 마지막 인덱스에 도달했을 때 합계를 추가해준다.
return
get_all_ways_to_by_doing_plus_or_minus(array, current_index + 1, current_sum + array[current_index], all_ways)
get_all_ways_to_by_doing_plus_or_minus(array, current_index + 1, current_sum - array[current_index], all_ways)
# 마지막 요소를 더하거나 빼준다
get_all_ways_to_by_doing_plus_or_minus(numbers, 0, 0, result)
print(set(result)) # 중복 제거를 위해 집합형으로 출력하지만 우리가 구하려는 것은 계산 결과의 모든 값이 아니라,
타겟값과 일치하는 경우의 수는 몇 가지가 있는지이다. 따라서 새로운 함수를 만들어서 작성하면 다음과 같다.
numbers = [1, 1, 1, 1, 1]
target_number = 3
result_count = 0 #target과 같은 모든 경우의 수를 담기 위한 변수
# 최종 목적은 target과 일치하는 경우의 수를 찾는 것이다.
# target을 변수로 설정하고, all_ways 대신 all_ways_count를 센다.
def get_count_of_ways_to_target_by_doing_plus_or_minus(array, target, current_index, current_sum):
if current_index == len(array):
if current_sum == target: #target과 일치하는 경우
global result_count #함수 외부에서 정의된 변수를 내부에서 쓰기 위함
result_count += 1
return
get_count_of_ways_to_target_by_doing_plus_or_minus(array, target, current_index + 1, current_sum + array[current_index])
get_count_of_ways_to_target_by_doing_plus_or_minus(array, target, current_index + 1, current_sum - array[current_index])
get_count_of_ways_to_target_by_doing_plus_or_minus(numbers, target_number, 0, 0)
print(result_count)정답을 힐끔힐끔 봐가면서 코드를 고치는 과정에서 글로벌 변수에 대해 알게 되었다.
글로벌 변수는 함수 외부에 정의되어 있는 변수를 내부에서 사용하기 위해서 써준다.
그냥 선언만 하면 됨. global 변수이름. 그리고 함수에서 안쓰는 변수는 지워주면 된다.
에휴 이번주에는 연습문제 난이도가 꽤 높았다.
이틀에 걸쳐서 하루는 개념을 익히고 연습문제를 풀었고, 나머지 하루는 복습하면서 숙제를 풀었다.
이제 남은 오후시간에는 3주차를 들어가야 한다. 아자뵤!
'자료구조, 알고리즘' 카테고리의 다른 글
| 자료구조, 알고리즘 3주차: 정렬, 스택, 큐, 해쉬, 아주 어려운 연습문제들... (1) | 2022.11.25 |
|---|---|
| 알고리즘 강의 3일차: 스택(push, pop, peek), 큐(enqueue, dequeue, peek), 정렬(버블, 선택, 삽입) (0) | 2022.11.25 |
| 알고리즘 강의 2일차: 시간 복잡도, 배열, 링크드리스트(Class, append, get_node, add_node) (0) | 2022.11.24 |
| 알고리즘 강의 1일차: 랜덤값 import random, 문자열 요약 배열 요소끼리 비교 (0) | 2022.11.23 |
| 자료구조, 알고리즘 1주차 (0) | 2022.11.22 |
